
Introduction
When you’re building intelligent agents to help developers – whether it’s a Code Review Agent, a Code Analysis Agent, or a full-fledged developer assistant – you quickly realize that simply having a high-performing LLM is not enough. What you need is control, extensibility, and the ability to integrate the model with tools, filesystems, and real workflows.
Through our own experimentation and internal evaluation, we ultimately chose Qwen’s QwQ-32B model and opted to self-host it instead of relying on inference providers.
In this article, we’ll walk you through the rationale behind that choice and the roadblocks we hit – and why it was absolutely worth it.
Why We Chose Qwen/QwQ-32B Over Other LLMs
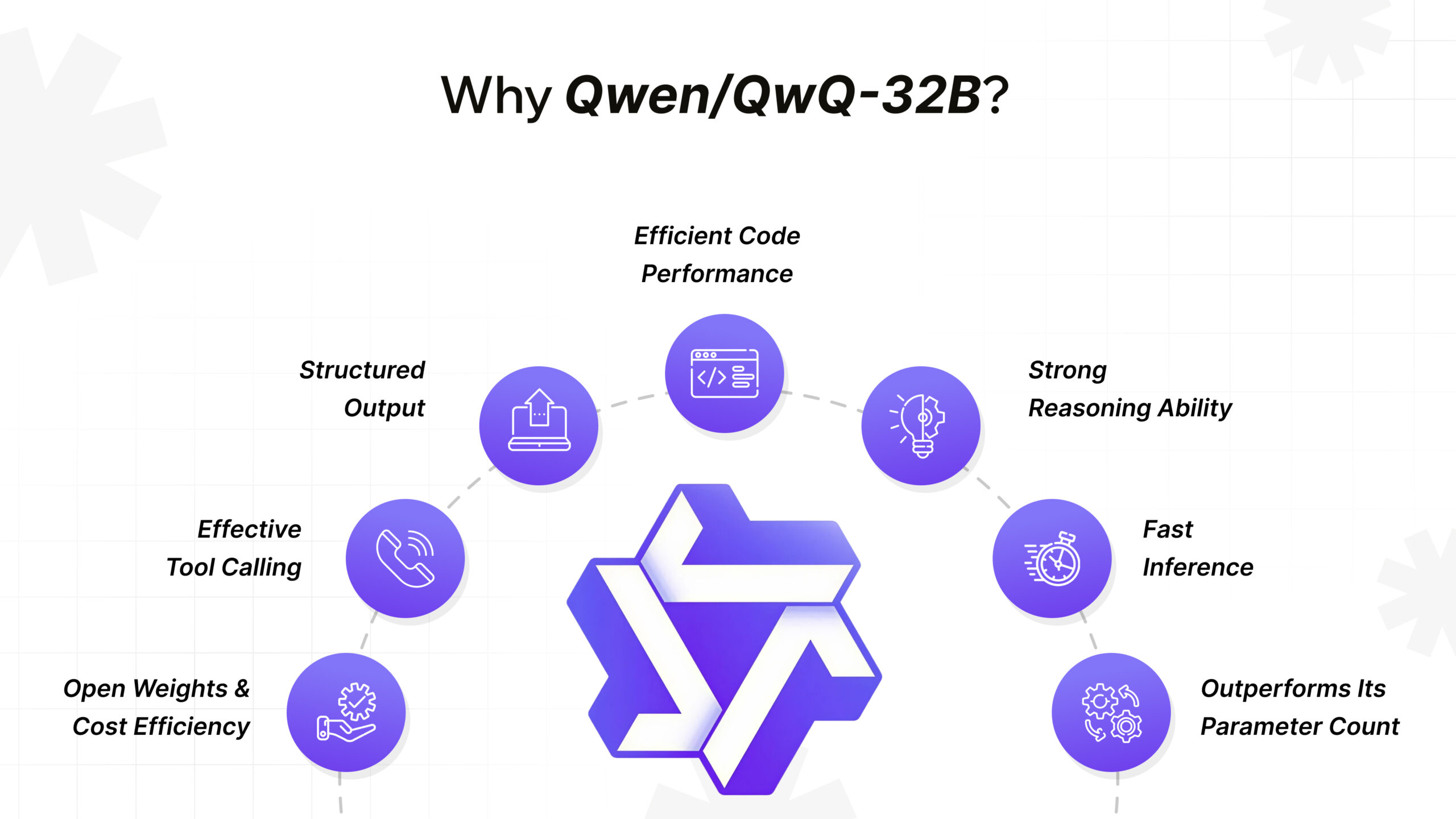
With a plethora of LLMs out there in the market, here’s why Qwen/QwQ-32B stood out to us:
- Structured Output: We needed models that could return structured, predictable responses – like JSON, file paths, and code metadata. QwQ-32B handles this smoothly, even for deeply nested schemas.
- Tool Calling: This isn’t a nice-to-have for our agents; it’s critical. QwQ-32B was designed with tool/function calling in mind and integrates easily with LangChain’s tool execution flows.
- Open Weights & Cost Efficiency: Access to open weights gave us full transparency and control – at a fraction of the price of closed APIs.
- Efficient Code Performance: Despite being smaller than some of the massive frontier models, QwQ-32B generates accurate, well-formatted, and context-aware code. It respects instructions, handles multi-file reasoning, and understands developer language really well.
- Strong Reasoning Ability: We were genuinely impressed by QwQ-32B’s step-by-step logic, especially when combined with the deepseek_r1 reasoning parser in vLLM. It breaks down problems cleanly and handles tasks like refactoring suggestions, bug spotting, and code explanation with clarity.
- Fast Inference: Thanks to its architectural efficiency and compatibility with vLLM, QwQ-32B offers strong throughput and latency without requiring extreme hardware (though it flies on an H100).
- Outperforms Its Parameter Count: Even at 32B parameters, it punches above its weight. In our testing, it performed at par with larger models (and sometimes even better) when the task required a mix of logic, structure, and code awareness.
Essentially, QwQ-32B is a balanced, developer-friendly model that does a lot with less – and gives you control while doing it.
Why We Moved Away from Managed Inference Providers
We began our journey by exploring managed inference providers. But as soon as we started testing tool calling, the limitations became excruciatingly clear.
We quickly ran into three major blockers:
- No tool calling support
- No clear visibility on precision or whether we were using fp16, int4, or bfloat16
- Limited or no access to advanced inference parameters
That was the tipping point. For the level of power and flexibility we needed, self-hosting became the only viable option.
How We Self-Hosted QwQ-32B with Full Tool Calling Support
We rented an Nvidia H100 SXM GPU from Hyperbolic.xyz – a great platform for raw GPU power without the fuss.
To deploy the model with tool calling, we used vLLM and launched it with the following command:
vllm serve Qwen/QwQ-32B \
–enable-reasoning –reasoning-parser deepseek_r1 \
–enable-auto-tool-choice –tool-call-parser hermes
To make the model accessible externally, we set up a secure ngrok tunnel. This allowed remote agents and services to interact with the model via a standard API interface.
Making Tools Available with LangChain MCP
To supercharge our agents, we exposed local tools to the model using the LangChain MCP Adapters.
The following tools were made MCP-compatible:
These let the model perform tasks such as list files, analyze codebases, and act on external data sources – just like a human developer would.
Sample Code: Testing Tool Calling with the Hosted Model
Here’s how we connected the self-hosted model and tested it with actual tools:
import asyncio from langchain_mcp_adapters.client import MultiServerMCPClient from langchain_openai import ChatOpenAI from langgraph.prebuilt import create_react_agent from typing import List from pydantic import BaseModel, Field class Schema(BaseModel): """Attributes: files: List of file names """ files: List[str] = Field(default_factory=list, description="List of file names") async def main(): model = ChatOpenAI( model="Qwen/QwQ-32B", temperature=0, base_url="<YOUR-MODEL-BASE-URL>/v1" ) def get_mcp_config(): return { "filesystem": { "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", "/Users/abhinav/Desktop/CAW/testing-folder"], "transport": "stdio" }, "think-tool": { "command": "npx", "args": ["-y", "think-tool-mcp"], "transport": "stdio" } } async with MultiServerMCPClient(get_mcp_config()) as mcp_client: tools = mcp_client.get_tools() graph = create_react_agent(model, tools=tools) prompt = "List files at /Users/abhinav/Desktop/CAW/testing-folder. Return a JSON Output with an array of file names. Format Instructions: {format_instructions}" inputs = { "messages": [("user", prompt.format( format_instructions=Schema.model_json_schema() ))] } res = await graph.ainvoke(inputs) print(res) if __name__ == "__main__": asyncio.run(main())
Just plug in your model’s base URL, and voila – your self-hosted LLM can now browse files like a human assistant.
Why Self-Hosting Was the Right Move
At first glance, self-hosting can feel like a high-effort path, but here’s why it was well worth the effort for us:
- Full Control: We chose the model, precision (bfloat16), inference logic, and tools.
- Tool Calling Support: A must-have for intelligent agent workflows.
- Scalability & Cost-Efficiency: This was vital, especially once we started moving beyond prototypes.
- Freedom to Innovate: We weren’t held back by the constraints of closed APIs, allowing us to push the limits of what our agents could do.
Thanks to platforms like HuggingFace and Hyperbolic, the entire setup went smoother than we expected.
Final Thoughts
If you’re serious about building advanced AI agents – especially ones that interact with code, filesystems, or structured data – you’ll quickly find that generic API access only takes you so far. Real control is what you need, and choosing Qwen/QwQ-32B and self-hosting it with vLLM gave us just that.
If you’re on a similar journey, don’t hesitate to go hands-on. It’s absolutely worth it.
And if you’d like help getting there, we can work with you.
At CAW, we help businesses identify use cases that are best solved using AI agents, rapidly prototype, and deploy custom, scalable agents into production.
If you wish to explore what tailor-made AI solutions can do for your business, let’s talk.

